We all know that traditional phone calls can sound pretty bad. The other person’s voice sounds tinny and weak, as if they were speaking to you from a metal box submerged 15 feet in motor oil. At least that’s how I’ve always thought of it. For years, nobody really complained about this, though, because a decrease in voice quality seemed a small price to pay for the miracle of being able to speak to anyone you want anywhere in the world at any time. Then came the popularization of smart phones and applications like Skype and FaceTime. “You sound really clear!” That’s what people usually say the first time I give them a FaceTime Audio call. But why is there such a big difference between traditional phone calls placed over the phone network and data-based apps that use the data network?
As it turns out, the answer to this question gets pretty technical, and leaves you mucking around in the world of Signal Processing, learning about what actually happens to get those vibrations we produce with our mouth meat into something that can be transmitted over time and space. Signal processing and all of its cousins and neighbors (like digital signal processing and digital image processing) are technologies which are so fundamental to every aspect of our modern life, that it seems worth understanding at least the basic outline of how they operate and have evolved over time.
In this post, I want to trace a very very basic outline of what is involved in signal processing, give some sense of how it’s used in our everyday life, and then use the case-study of the bad phone call quality to make signal processing’s wide-reaching effects seem a little more concrete.
Let’s start by defining some terms. I think it’s clear that when we talk about signal processing, we are talking about doing some kind of processing to a signal. Right. But what are we talking about when we talk about a “signal” here? Although this is applicable to all kinds of media, let’s keep it simple and think about audio signals: When you talk, sing, or clap your hands, you are creating pressures which cause the air around them to vibrate and create acoustic waves. Those waves are a signal, a physical or acoustic signal. This signal travels through the air and into your friend’s ears. You can say that your friend’s ears “receive” the signal. The acoustic waves slam into your friend’s ear drum, causing it to vibrate according to the same air pressure pattern that you created when you moved your lips. After some complicated brain stuff, your friend understands what it is that you said or sung.
When this signal is received by a microphone, however, the electronics inside the microphone create a new electrical signal which is a copy of original signal. We call this new electric signal an analog signal because the instantaneous voltage fluctuates analogously to the instantaneous pressure of the acoustic waves. If you were to make two graphs, one showing the changes in pressure over time of the acoustic signal and one showing the changes in voltage over time of the electric signal, the two graphs would look identical.
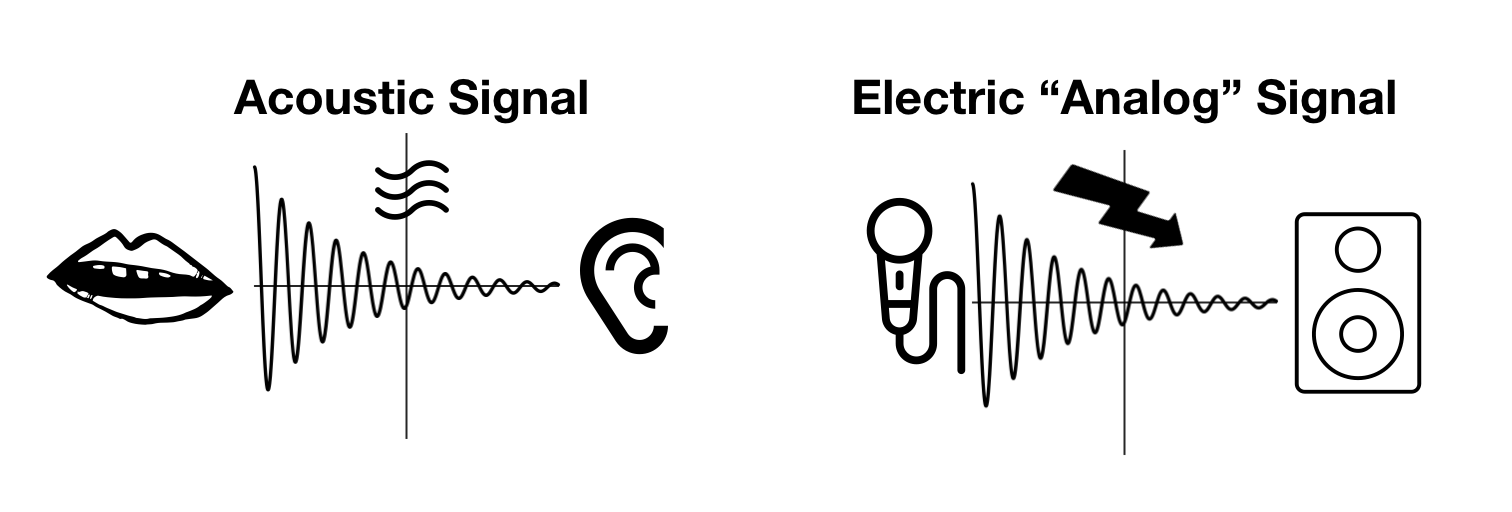
This technology began to be developed and tinkered with in the early 19th century, mostly in workshops and laboratories. It would take quite a while for it to reach commercially-viable deployment, but pause for a second to think of the implications of the creation of this analog signal: You could now make an analog copy of a physical signal—e.g. someone singing into a microphone—send that analog signal through some electrical wires to somewhere else and then recreate the physical signal. Someone singing on stage could now be amplified through the aid of speakers so that everyone could hear them, and cousins living in distant towns could now speak to each other with the telephone. People even found ways of using these analog signals to transmit sounds across time by scratching the analog signal into a wax disc so that the signal could be read and recreated later. Eventually, vinyl records and magnetic tape replaced these wax discs, but the fundamental principle was still the same.
Ok, now that we have an idea of what a signal is and what the stakes surrounding transmitting signals were, let’s get into the processing of them. Transmitting these analog signals across time and space was surely a technological development worthy of being called a miracle, but it was pretty complicated and, above all, costly to do this. In the beginning of telephony, each phone had to have a cable running directly to the phone it was connecting to. The advent of switchboards and operators mitigated this complexity a bit, but there still needed to be a lot of electrical wires to connect everybody.
In the late 19th century, engineers working on telegraph systems devised a way to send multiple messages simultaneously along a single wire. This process was called multiplexing because it allowed multiple incoming signals to be composed into one complex signal that could be sent down the line and decomposed at the other end back into its individual signals. This dramatically increased the efficiency of sending telegraphs, lowering costs, and opening the technology to more people. This kind of multiplexing was a key moment in the history of telephonic signal processing, and formed the foundation for other communication and broadcast technologies like AM/FM radio, broadcast television, and, of course, telephone networking.
Telephone engineers in the ‘40s and ‘50s began experimenting with rudimentary digital signal processing in order to fit more simultaneous telephone calls onto a single line. Unlike physical and analog signals, which are continuous, digital signals are discrete. What’s the difference? Remember how when discussing physical and analog signals, we noted that they could be expressed as a graph of some fluctuation (pressure, voltage, etc.) over time? That is because those signals are continuous. At any given point in time, there exists a value of the independent variable that we care about (again, for our purposes, pressure or voltage). With discrete signals, this is a little different. Take a look at the following graphic:
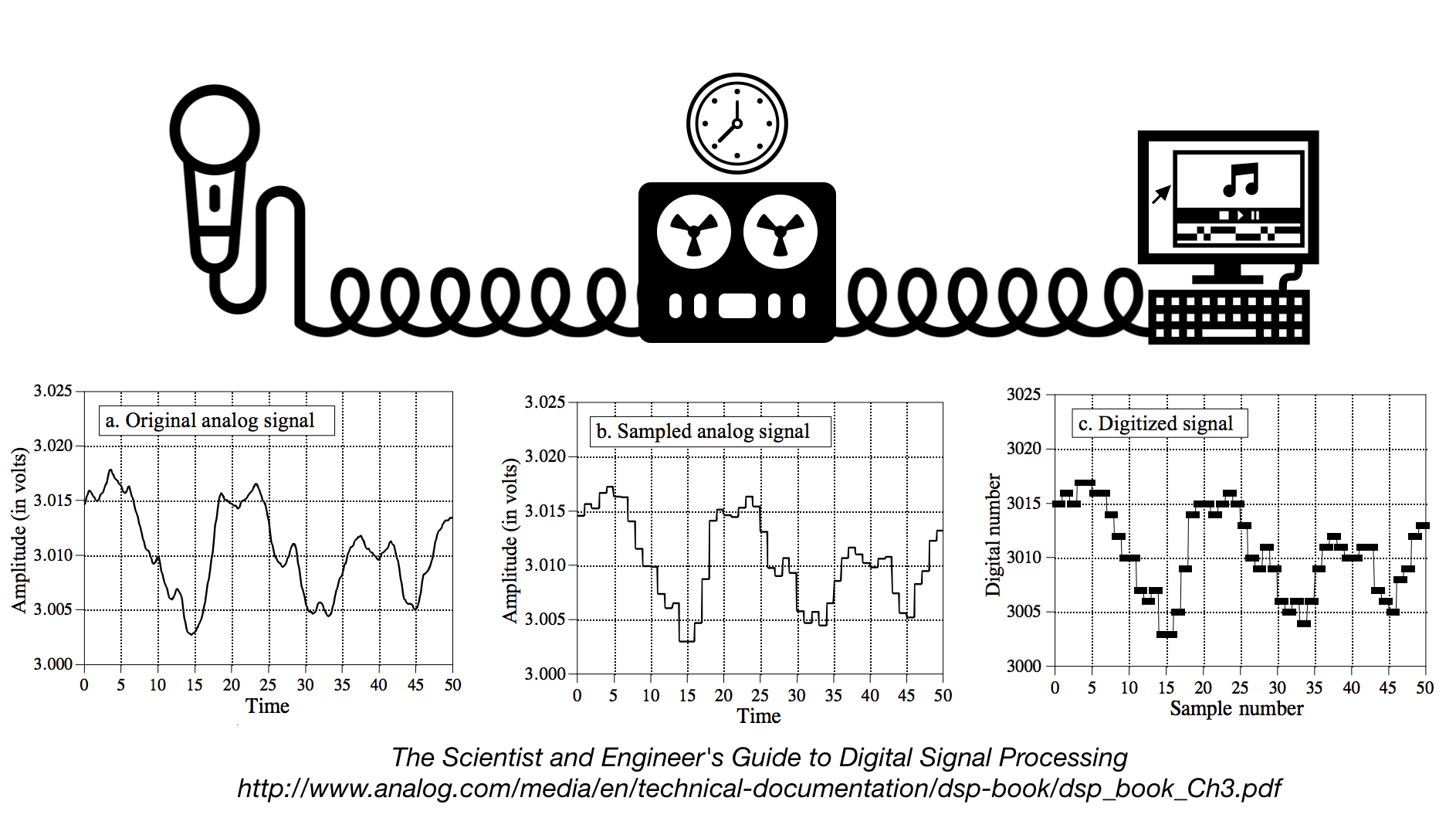
On the left, you have the analog signal produced by a microphone. On its way to becoming a digital signal it is sampled by some kind of device. This device takes samples, individual measurements of the independent variable of interest, at a certain rate, called the sample rate. For modern audio devices, a common sample rate is around 40–50 thousand times per second. These data gathered from these samples is then converted to digital information in the form of 1’s and 0’s by an analog-to-digital converter and stored in memory. Just as the analog signals which were scratched onto vinyl records were a way of storing a copy of a signal for later use in recreation, the digitization process is the modern process which allows for the creation of .mp3 files.
With regard to sampling, the core process by which an analog signal gets converted to a digital one, there is a simple rule to keep in mind: The more samples per second you take from an analog signal, the higher the fidelity of your digital signal will be. But there is a flip-side to this. The more samples you take, the more information you have to store, and in the case of telephone communications, that means more digital information that you have to transmit in real time over a network.
In the interest of keeping costs down and being able to multiplex as many simultaneous calls as possible into a signal line, phone companies found that the ideal sampling rate for phone calls was around 8,000 samples per second. For a variety of technical reasons, this rate allows phones to capture the minimum range of frequencies required for comprehensive human speech, somewhere between 300–3500 Hz. For comparison, the human ear can hear between about 20–20,000Hz, but most of the sounds of human speech fall within the 300–3500Hz range, with the notable exceptions of sibilant sounds like f, v, s, and z.
But why do FaceTime Audio calls sound so much better? Due to improvements in things like audio codecs and data-transmission (technologies like 3G and 4G), applications like FaceTime Audio are able to send audio data that was sampled at 24,000 time per second (3x faster than traditional phones) over the network without significant delay or data usage. Even though it is annoying that phone calls can sound as lousy as they do, it’s important to remember the historical reasons for the tradeoff, even if phone companies really aren’t beholden to the same burdening factors as in the mid-20th century, when the 8,000 samples per second rate was decided upon. As for why we still live with this quality difference… good question. I, too, as someone working in audio, would like to know.
The same signal processing technologies that undergird the phone system are at play in almost every facet of our modern lives, too. Video streaming, medical equipment, meteorological observation, and image display all rely on the technology of sampling and contend with the same tradeoffs of fidelity v.s. size.